This paper makes three major points:
(1)
Levin search by itself can be useful for solving POMDPs.
This has been demonstrated with a non-trivial,
partially observable maze
containing significantly more states and obstacles than
those used to demonstrate the usefulness of previous
POMDP algorithms,
e.g., [McCallum, 1993,Ring, 1994,Littman, 1994,Cliff and Ross, 1994]:
for instance,
McCallum's cheese maze has only 11 free fields,
and Ring's largest maze is a 9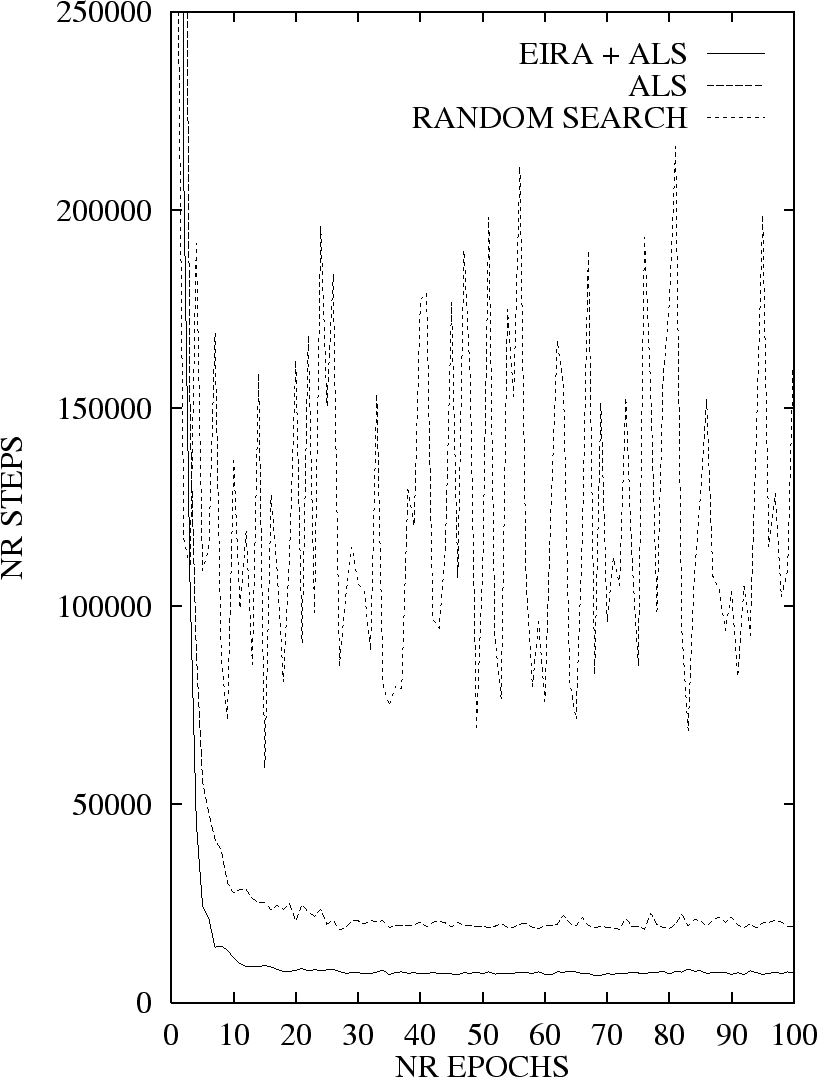 9-maze.
This also illustrates that search in program space can have significant
advantages over methods searching through simple action space,
provided the algorithmic complexity of the solutions is low.
(2)
A straightforward, incremental, adaptive extension of non-incremental LS
(ALS -- introduced in this paper)
can dramatically reduce the time consumed by successive calls of LS
in cases where there are multiple tasks to solve.
(3)
ALS can further significantly benefit from
``environment-independent reinforcement acceleration'' (EIRA).
EIRA helps to get rid of ALS-generated
policy modifications for which there is no evidence
that they contribute
to long-term performance improvement.
This actually provides the first example of how
EIRA can improve heuristic learning methods in lifelong
learning situations.
Due to EIRA's generality (it is not limited to run in
conjunction with ALS, but
can be combined with all kinds
of policy modifying learning algorithms), these results
add to making EIRA appear a promising, general paradigm.
9-maze.
This also illustrates that search in program space can have significant
advantages over methods searching through simple action space,
provided the algorithmic complexity of the solutions is low.
(2)
A straightforward, incremental, adaptive extension of non-incremental LS
(ALS -- introduced in this paper)
can dramatically reduce the time consumed by successive calls of LS
in cases where there are multiple tasks to solve.
(3)
ALS can further significantly benefit from
``environment-independent reinforcement acceleration'' (EIRA).
EIRA helps to get rid of ALS-generated
policy modifications for which there is no evidence
that they contribute
to long-term performance improvement.
This actually provides the first example of how
EIRA can improve heuristic learning methods in lifelong
learning situations.
Due to EIRA's generality (it is not limited to run in
conjunction with ALS, but
can be combined with all kinds
of policy modifying learning algorithms), these results
add to making EIRA appear a promising, general paradigm.
Future Work. ALS should be extended such that it not only adapts the probability distribution underlying LS, but also the initial time limit required by LS' first phase (the current ALS version keeps the latter constant, which represents a potential loss of efficiency). Again, EIRA should be combined with this ALS extension.
EIRA should also be combined with other (e.g., genetic) learning algorithms, especially in situations where the applicability of a given algorithm is questionable because the environment does not satisfy the preconditions that would make sound. EIRA can at least guarantee that those of 's policy modifications that appear to have negative long-term effects on further learning processes are countermanded. Indeed, in separate POMDP experiments we were already able to show that EIRA can improve standard Q-learning's performance (recall that POMDP applications of Q-learning are not theoretically sound, although many authors do apply Q-variants to POMDPs). Another interesting application area may be the field of bucket-brigade based classifier systems: [Cliff and Ross, 1994] show that such systems tend to be unstable and forget good solutions. Here EIRA could unfold its safety belt effect.