Machine learning and the prior problem.
In machine learning applications, we are often concerned
with the following problem:
given training data ![]() , we would like to select
the most probable hypothesis
, we would like to select
the most probable hypothesis ![]() generating the data.
Bayes formula yields
generating the data.
Bayes formula yields
| (1) |
Universal prior
(Levin, 1974; Solomonoff, 1964; Gacs, 1974; Chaitin, 1975).
Define ![]() , the a priori probability of a bitstring
, the a priori probability of a bitstring ![]() ,
as the probability of guessing a halting program
that computes
,
as the probability of guessing a halting program
that computes ![]() on universal TM
on universal TM ![]() .
Here, the way of guessing is defined
by the following procedure:
whenever the scanning head of
.
Here, the way of guessing is defined
by the following procedure:
whenever the scanning head of ![]() 's input tape (initially blank)
shifts right to a field that has not been scanned before, do:
With probability
's input tape (initially blank)
shifts right to a field that has not been scanned before, do:
With probability ![]() fill it with a 0;
with probability
fill it with a 0;
with probability ![]() fill it with a 1.
We obtain
fill it with a 1.
We obtain
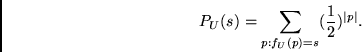
Dominance of shortest programs.
It can be shown
(Levin, 1974; Chaitin, 1975)
that
Dominance of universal prior.
Suppose there are infinitely many enumerable solution candidates (strings):
amazingly, ![]() dominates all discrete enumerable semimeasures P
(including probability distributions, see e.g. Li and Vitanyi (1993)
for details) in the following sense:
for each
dominates all discrete enumerable semimeasures P
(including probability distributions, see e.g. Li and Vitanyi (1993)
for details) in the following sense:
for each ![]() there is a constant
there is a constant ![]() such that
such that
![]() for
all strings
for
all strings ![]() .
.
Since Kolmogorov complexity is incomputable in general, the universal prior is so, too. A popular myth states that this fact renders useless the concepts of Kolmogorov complexity, as far as practical machine learning is concerned. But this is not so, as will be seen next. There we focus on a natural, computable, yet very general extension of Kolmogorov complexity.
Levin complexity.
In what follows, a (not necessarily halting) program is
a string on ![]() 's input tape which can be
scanned completely by
's input tape which can be
scanned completely by ![]() .
Let
.
Let ![]() scan a program
scan a program ![]() before it finishes printing
before it finishes printing ![]() onto the work tape.
Let
onto the work tape.
Let ![]() be the number of steps taken before
be the number of steps taken before ![]() is printed. Then
is printed. Then
Levin's universal optimal search algorithm
(Levin, 1973; 1984).
Suppose we are looking for the solution (a string) to a given problem.
Levin's universal search algorithm generates
and evaluates all
strings (solution candidates) in order of their ![]() complexity,
until a solution is found.
This is essentially equivalent to
enumerating
all programs in order of decreasing probabilities, divided
by their runtimes.
Each program computes a string that
is tested to see whether it is a solution to the given problem.
If so, the search is stopped.
Amazingly, for a broad class of problems,
including inversion problems and
time-limited optimization problems,
universal search
can be shown to be optimal with respect to total expected
search time,
leaving aside a constant factor independent of the problem size:
if string
complexity,
until a solution is found.
This is essentially equivalent to
enumerating
all programs in order of decreasing probabilities, divided
by their runtimes.
Each program computes a string that
is tested to see whether it is a solution to the given problem.
If so, the search is stopped.
Amazingly, for a broad class of problems,
including inversion problems and
time-limited optimization problems,
universal search
can be shown to be optimal with respect to total expected
search time,
leaving aside a constant factor independent of the problem size:
if string ![]() can be computed within
can be computed within ![]() time steps
by a program
time steps
by a program ![]() , and the probability of guessing
, and the probability of guessing ![]() (as above) is
(as above) is ![]() ,
then within
,
then within
![]() time steps,
systematic enumeration according to Levin will
generate
time steps,
systematic enumeration according to Levin will
generate ![]() , run it for
, run it for ![]() time steps,
and output
time steps,
and output ![]() .
In the experiments below, a probabilistic algorithm strongly inspired
by universal search will be used.
.
In the experiments below, a probabilistic algorithm strongly inspired
by universal search will be used.