Zum Zeitpunkt ![]() der Sequenz
der Sequenz ![]() ist
ist
![]() die (weiter unten zu definierende) Eingabe eines
Autoassoziators
die (weiter unten zu definierende) Eingabe eines
Autoassoziators
![]() mit
mit ![]() versteckten Knoten,
versteckten Knoten,
![]() Eingabeknoten, und
Eingabeknoten, und
![]() Ausgabeknoten.
Ausgabeknoten.
![]() 's interner Zustandsvektor (ablesbar von einem
`Flaschenhals' versteckter Knoten) heißt
's interner Zustandsvektor (ablesbar von einem
`Flaschenhals' versteckter Knoten) heißt
![]() .
.
![]() 's
's ![]() -dimensionaler Ausgabevektor
wird mit
-dimensionaler Ausgabevektor
wird mit ![]() bezeichnet. Zu jedem Zeitschritt
bezeichnet. Zu jedem Zeitschritt ![]() versucht
versucht
![]() mittels BP, seine eigene Eingabe zu rekonstruieren.
mittels BP, seine eigene Eingabe zu rekonstruieren.
![]() 's Zielfunktion ist dabei
's Zielfunktion ist dabei
Zum Zeitpunkt ![]() der Sequenz
der Sequenz ![]() erhält ein azyklisches BP-Netz
erhält ein azyklisches BP-Netz
![]() den Vektor
den Vektor
![]() als Eingabe.
Um die Dinge nicht über Gebühr zu verkomplizieren, nehmen
wir auf (theoretisch eigentlich notwendige) eindeutige
Zeitrepräsentationen keine Rücksicht.
als Eingabe.
Um die Dinge nicht über Gebühr zu verkomplizieren, nehmen
wir auf (theoretisch eigentlich notwendige) eindeutige
Zeitrepräsentationen keine Rücksicht.
![]() 's
's ![]() -dimensionaler Ausgabevektor
-dimensionaler Ausgabevektor ![]() soll nach
der Trainingsprozedur die Wahrscheinlichkeitsverteilung der
möglichen
soll nach
der Trainingsprozedur die Wahrscheinlichkeitsverteilung der
möglichen ![]() approximieren. Daher wird
approximieren. Daher wird ![]() so
normalisiert,
daß stets
so
normalisiert,
daß stets
![]() gilt (siehe z.B. Abschnitt 5.3).
Für
gilt (siehe z.B. Abschnitt 5.3).
Für ![]() sind
sind ![]() und
und ![]() folgendermaßen definiert:
folgendermaßen definiert:
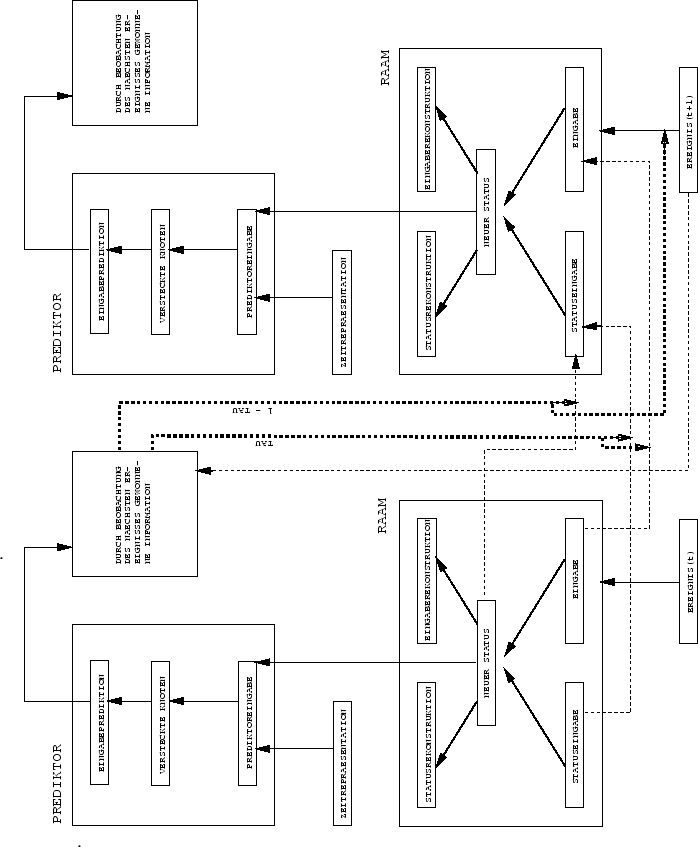 |
Der Effekt dieses Vorgehens ist: Solange sich die nächste
Eingabe aus der vorherigen Eingabe und dem vorherigen
reduzierten Zustand als (nahezu) vorhersagbar erweist,
bleibt die Eingabe des Autoassoziators im wesentlichen invariant.
Nur die wirklich unerwarteten Ereignisse generieren
neue Zielwerte für ![]() - damit wird
- damit wird ![]() dazu angehalten, ausschließlich informationstragende Ereignisse
in seine
internen Repräsentationen einzubinden.
Es sollte erwähnt werden, daß obige Methode wiederum
nur eine von mehreren
Möglichkeiten darstellt, das grundlegende Prinzip zu
implemetieren.
dazu angehalten, ausschließlich informationstragende Ereignisse
in seine
internen Repräsentationen einzubinden.
Es sollte erwähnt werden, daß obige Methode wiederum
nur eine von mehreren
Möglichkeiten darstellt, das grundlegende Prinzip zu
implemetieren.