


|
Deep Learning since our Annus Mirabilis 1990-91: First very deep learners, and first to win official contests in pattern recognition, object detection, image segmentation, sequence learning, through fast & deep / recurrent neural networks. Jürgen Schmidhuber (compare 2012 interview on KurzweilAI and G+ posts). Click at the images for more detailed overview pages and videos! Deep Learning in Artificial Neural Networks (NNs) is about credit assignment across many (not just a few) subsequent computational stages or layers, in deep or recurrent NNs. To our knowledge, the ancient expression "Deep Learning" was introduced to the NN field by Aizenberg & Aizenberg & Vandewalle's book (2000) - more in this G+ post. The field itself is much older though. The first Deep Learning systems of the feedforward multilayer perceptron type were created half a century ago (Ivakhnenko et al., 1965, 1967, 1968, 1971). The 1971 paper already described an adaptive deep network with 8 layers of neurons. (Our first general purpose recurrent Deep Learners were published much later, in 1991 - more below.) Recently the field has experienced a resurgence. Since 2009, our Deep Learning team has won 9 (nine) first prizes in important and highly competitive international pattern recognition competitions (with secret test set known only to the organisers), far more than any other team. Our neural nets also were the first Very Deep Learners to win such contests (e.g., on classification, object detection, segmentation), and the first machine learning methods to reach superhuman performance in such a contest. Since 2009-2011, this has attracted enormous attention from industry. Here the list of won competitions (details in the rightmost column): 9. MICCAI 2013 Grand Challenge on Mitosis Detection
Our Deep Learning methods also set records in important Machine Learning (ML) benchmarks (details again in the rightmost column): D. Chinese characters from the ICDAR 2013 competition (3755 classes)
Remarkably, none of 1-9 & A-D above required the traditional sophisticated computer vision techniques developed over the past six decades or so. Instead, our biologically rather plausible systems are inspired by human brains, and learn to recognize objects from numerous training examples. We use deep, artificial, supervised, feedforward or recurrent (deep by nature) neural networks with many non-linear processing stages. We started work on Very Deep Learning a quarter-century ago. Back then, Sepp Hochreiter (now professor) was an undergrad student working on Schmidhuber's neural net project. His 1991 thesis [2b] is a Deep Learning milestone: it formally showed that deep networks like the above are hard to train because they suffer from the now famous problem of vanishing or exploding gradients. Since then we have developed various techniques to overcome this obstacle (more here). The first system of 1991 used a stack of recurrent neural networks (RNNs) pre-trained in unsupervised fashion [2a,2c] to compactly encode input sequences, where lower layers of the hierarchy learn to extract compact sequence representations fed to higher layers. This can greatly accelerate subsequent supervised learning [2a,2c]. See [2c] for an experiment with 1200 nonlinear virtual layers. The 1991 system also was the first Neural Hierarchical Temporal Memory. Today, computing is almost a million times cheaper than it was in 1991. We use graphics cards or GPUs (mini-supercomputers for video games, see picture in 2nd column) to speed up learning on standard CPUs by a factor of up to 50. In 2010, we broke the MNIST (benchmark C) record through GPU-based plain backprop for standard NNs (no unsupervised pre-training, no convolution etc) [6]. Our committees of networks improve the results even further [9-13,17-19]. Pattern recognition through Deep Learning is becoming important for thousands of practical applications. For example, the future of search engines lies in image and video recognition as opposed to traditional text search. Autonomous robots such as driverless cars can greatly profit from it, too (see competitions 4,6). Deep Learning may even have lifesaving impact through medical applications such as cancer detection, perhaps the most important application area, with the highest potential impact (see competitions 8,9). Reference [14] uses fast deep nets to achieve superior hand gesture recognition. Reference [16] uses them to achieve superior steel defect detection, three times better than support vector machines (SVM) trained on commonly used feature descriptors. Note that the successes 1-9 & A-D above did NOT require any unsupervised pre-training, which is a bit depressing, as we have developed unsupervised learning algorithms for over 25 years. However, the feature detectors (FDs) discovered by our supervised systems resemble those found by our old unsupervised methods such as Predictability Minimization [2e,2g,2h] and Low-Complexity Coding and Decoding (LOCOCODE)[2i].
More Deep Learning Web Sites: Since Sept 2013: G+ posts on Deep Learning 2014: Deep Learning in Neural Networks: An Overview (invited survey, with a history of Deep Learning since the 1960s, 88 pages, 888 references) 2014: Who Invented Backpropagation? (History of Deep Learning's central algorithm 1960-1970-1981 and beyond) Deep NNs win MICCAI 2013 Grand Challenge and 2012 ICPR Contest on Mitosis Detection (first Deep Learner to win a contest on object detection in large images) Deep NNs win 2012 Brain Image Segmentation Contest (first image segmentation competition won by a feedforward Deep Learner) 2012: 8th international pattern recognition contest won since 2009 2011: First superhuman visual pattern recognition in a limited domain (twice better than humans, three times better than the closest artificial competitor, six times better than the best non-neural method) 2009: First official international pattern recognition contests won by Very Deep Learning (connected handwriting through LSTM RNNs: simultaneous segmentation and recognition) 1997: First purely supervised Very Deep Learner JS' first Deep Learner of 1991 + Deep Learning Timeline 1965-2013 (also summarises the origins of backpropagation, still central for Deep Learning) 1991: Fundamental Deep Learning Problem discovered and analysed and partially solved 2015: Critique of paper by self-proclaimed "Deep Learning Conspiracy" (Nature 521 p 436) 2009 Computer Vision site (precursor of present site) 2013: Compressed Network Search for reinforcement learning RNN video game controllers (> 1,000,000 weights) learning from scratch, using high-dim visual input streams. Industrial Impact. Apple / Google / Microsoft / Amazon / IBM / Baidu / others are using our recurrent neural networks (especially LSTM) to improve speech recognition, machine translation, image caption generation, syntactic parsing / text-to-speech synthesis, photo-real talking heads / prosody detection / more speech recognition / video-to-text translation, and many other important applications. For example, our LSTM is in Amazon's Alexa, in Facebook's and Google's Machine Translation, in Apple's iPhone, in Google's speech recognition on Android phones and Google's automatic email answering. Some earlier benchmark records achieved with the help of deep LSTM RNNs, often at big IT companies: Text-to-speech synthesis (Fan et al., Microsoft, Interspeech 2014), Language identification (Gonzalez-Dominguez et al., Google, Interspeech 2014), Large vocabulary speech recognition (Sak et al., Google, Interspeech 2014), Prosody contour prediction (Fernandez et al., IBM, Interspeech 2014), Medium vocabulary speech recognition (Geiger et al., Interspeech 2014), Machine translation (Sutskever et al., Google, NIPS 2014), Audio onset detection (Marchi et al., ICASSP 2014), Social signal classification (Brueckner & Schulter, ICASSP 2014), Arabic handwriting recognition (Bluche et al., DAS 2014), TIMIT phoneme recognition (Graves et al., ICASSP 2013), Optical character recognition (Breuel et al., ICDAR 2013).
Related articles and interviews (2012-16):
WIRED (Nov 2016),
Bloomberg (Jan 2017),
NY Times (Nov 2016, front page),
Financial Times (Nov 2016, also here),
ACM (long interview of Oct 2016, also
IT World &
NPA),
Inverse (Dec 2016),
Intl. Business Times (Feb 2016),
BeMyApp (Mar 2016),
Informilo (Jan 2016),
InfoQ (Mar 2016).
Also in leading German language newspapers:
ZEIT (May 2016,
ZEIT online in June),
Spiegel (Europe's top news magazine, Feb 2016),
NZZ 1 & 2 (August 2016),
Tagesanzeiger (Sep 2016),
Beobachter (Sep 2016),
CHIP (April 2016),
Computerwoche (July 2016),
WiWo (Jan 2016),
Spiegel (Jan 2016),
Focus (Mar 2016),
Welt (Mar 2016),
SZ (Mar 2016),
FAZ (Dec 2015, title page),
NZZ (Nov 2015).
More in
Netzoekonom (Mar 2016),
Performer (Oct 2016),
WiWo (Feb 2016),
Focus (Jan 2016),
Bunte (Jan 2016). Earlier:
Handelsblatt (Jun 2015),
INNS Big Data (Feb 2015),
KurzweilAI (Nov 2012)
|


|
Our simple training algorithms for deep, wide, often recurrent, artificial neural networks similar to biological brains have won competitions on a routine basis and yield best known results on many famous benchmarks for computer vision, speech recognition, etc. Shown in this page are example images of traffic signs, Chinese characters, connected handwriting, human tissue, sliced brains, etc. |
|
We are currently experiencing a second Neural Network ReNNaissance (title of JS' IJCNN 2011 keynote) - the first one happened in the 1980s and early 90s. In many applications, our deep NNs are now outperforming all other methods including the theoretically less general and less powerful support vector machines (which for a long time had the upper hand, at least in practice). Check out the, in hindsight, not too optimistic predictions of our RNNaissance workshop at NIPS 2003, and compare the RNN book preface. Some of the (ex-)members of our Deep Learning Team: Sepp Hochreiter, Felix Gers, Alex Graves, Dan Ciresan, Ueli Meier, Jonathan Masci. For medical imaging, sine 2012 we also have worked with Alessandro Giusti in the group of Luca Maria Gambardella. Our work builds on earlier work by great pioneers including Ivakhnenko, Bryson, Kelley, Dreyfus, Linnainmaa, Werbos, Fukushima, Amari, Williams, LeCun, Weng, von der Malsburg, Kohonen, and others (more history here and especially in this historical survey).
[31]
J. Schmidhuber.
Deep Learning in Neural Networks: An Overview.
Neural Networks, Volume 61, January 2015, Pages 85-117, published online in 2014 (DOI: 10.1016/j.neunet.2014.09.003). Draft of invited survey (88 pages, 888 references):
Preprint IDSIA-03-14 / arXiv:1404.7828 [cs.NE];
version
v4 (PDF, 8 Oct 2014);
LATEX source;
complete public BIBTEX file (888 kB).
(Older PDF versions:
v1 of 30 April;
v1.5 of 15 May;
v2 of 28 May;
v3 of 2 July.)
HTML overview page.
[30]
J. Schmidhuber.
Deep Learning.
Scholarpedia, 10(11):32832, 2015.
[29]
J. Schmidhuber.
On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models.
Report arXiv:1210.0118 [cs.AI], 2015.
[28]
K. Greff, R. K. Srivastava, J. Schmidhuber. Training Very Deep Networks. Advances in Neural Information Processing Systems (NIPS), 2015.
Preprints arxiv:1505.00387 (May 2015)
and arXiv:1507.06228 (Jul 2015).
The first working very deep feedforward nets with over 100 layers. Let g, t, h, denote non-linear differentiable functions. Each non-input layer of our highway net computes g(x)x + t(x)h(x), where x is the data from the previous layer. (Like LSTM with forget gates for RNNs.) Microsoft's resnets are a special case of this where g(x)=t(x)=const=1.
[27]
M. Stollenga, W. Byeon, M. Liwicki, J. Schmidhuber. Parallel Multi-Dimensional LSTM, With Application to Fast Biomedical Volumetric Image Segmentation. Advances in Neural Information Processing Systems (NIPS), 2015, in press.
Preprint: arxiv:1506.07452.
[26]
M. Stollenga, J.Masci, F. Gomez, J. Schmidhuber.
Deep Networks with Internal Selective Attention through Feedback Connections.
Preprint arXiv:1407.3068 [cs.CV].
Advances in Neural Information Processing Systems (NIPS), 2014.
[25] J. Koutnik, K. Greff, F. Gomez, J. Schmidhuber. A Clockwork RNN. Proc. 31st International Conference on Machine Learning (ICML), p. 1845-1853, Beijing, 2014. Preprint arXiv:1402.3511 [cs.NE].
[24]
R. K. Srivastava, J. Masci, S. Kazerounian, F. Gomez, J. Schmidhuber. Compete to Compute. In Proc. Neural Information Processing Systems (NIPS) 2013, Lake Tahoe.
PDF.
[23]
D. Ciresan, J. Schmidhuber. Multi-Column Deep Neural Networks for Offline Handwritten Chinese Character Classification. Preprint arXiv:1309.0261, 1 Sep 2013.
[22]
J. Masci, A. Giusti, D. Ciresan, G. Fricout, J. Schmidhuber. A Fast Learning Algorithm for Image Segmentation with Max-Pooling Convolutional Networks. ICIP 2013. Preprint arXiv:1302.1690.
On object detection in large images, now scanned by our deep networks 1500 times faster than with previous methods.
[21]
A. Giusti, D. Ciresan, J. Masci, L.M. Gambardella, J. Schmidhuber. Fast Image Scanning with Deep Max-Pooling Convolutional Neural Networks. ICIP 2013. Preprint arXiv:1302.1700
[20]
D. Ciresan, A. Giusti, L. M. Gambardella, J. Schmidhuber. Mitosis Detection in Breast Cancer Histology Images using Deep Neural Networks. MICCAI 2013. PDF.
[19]
D. Ciresan, U. Meier, J. Schmidhuber.
Transfer Learning for Latin and Chinese Characters with Deep Neural Networks.
Proc. IJCNN 2012, p 1301-1306, 2012.
PDF.
Pretrain on one data set, profit on another.
[18]
D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber.
Multi-Column Deep Neural Network for Traffic Sign Classification.
Neural Networks 32, p 333-338, 2012.
PDF of preprint.
(First
superhuman visual pattern recognition.)
[17]
D. C. Ciresan, U. Meier, J. Schmidhuber.
Multi-column Deep Neural Networks for Image Classification.
IEEE Conf. on Computer Vision and Pattern Recognition CVPR 2012, p 3642-3649, 2012.
PDF.
Longer preprint
arXiv:1202.2745v1 [cs.CV].
[16]
J. Masci, U. Meier, D. Ciresan, G. Fricout, J. Schmidhuber.
Steel Defect Classification with Max-Pooling Convolutional Neural Networks.
Proc. IJCNN 2012. PDF.
[15]
D. Ciresan, A. Giusti, L. Gambardella, J. Schmidhuber.
Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images.
In Advances in Neural Information Processing Systems (NIPS 2012), Lake Tahoe,
2012. PDF. (See also
ISBI EM Competition Abstracts.)
[14]
J. Nagi, F. Ducatelle, G. A. Di Caro, D. Ciresan, U. Meier, A. Giusti, F. Nagi, J. Schmidhuber, L. M. Gambardella. Max-Pooling Convolutional Neural Networks for Vision-based Hand Gesture Recognition. Proc. 3rd IEEE Intl. Conf. on Signal & Image Processing and Applications (ICSIPA), Kuala Lumpur, 2011.
PDF.
[13]
J. Schmidhuber, D. Ciresan, U. Meier, J. Masci, A. Graves.
On Fast Deep Nets for AGI Vision.
In Proc. Fourth Conference on Artificial General Intelligence (AGI-11),
Google, Mountain View, California, 2011.
PDF.
Video.
[12]
D. C. Ciresan, U. Meier, L. M. Gambardella, J. Schmidhuber.
Convolutional Neural Network Committees For Handwritten Character Classification.
11th International Conference on Document Analysis and Recognition (ICDAR 2011),
Beijing, China, 2011.
PDF.
[11]
U. Meier, D. C. Ciresan, L. M. Gambardella, J. Schmidhuber.
Better Digit Recognition with a Committee of Simple Neural Nets.
11th International Conference on Document Analysis and Recognition (ICDAR 2011),
Beijing, China, 2011.
PDF.
[10]
D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber.
A Committee of Neural Networks for Traffic Sign Classification.
International Joint Conference on Neural Networks (IJCNN-2011, San Francisco), 2011.
PDF.
[9]
D. C. Ciresan, U. Meier, L. M. Gambardella, J. Schmidhuber.
Handwritten Digit Recognition with a Committee of Deep Neural Nets on GPUs.
ArXiv Preprint
arXiv:1103.4487v1 [cs.LG], 23 Mar 2011.
[8]
D. C. Ciresan, U. Meier, J. Masci, L. M. Gambardella, J. Schmidhuber.
Flexible, High Performance Convolutional Neural Networks for Image Classification.
International Joint Conference on Artificial Intelligence (IJCAI-2011, Barcelona), 2011. PDF.
ArXiv preprint, 1 Feb 2011.
Describes our special breed of GPU-based max-pooling convolutional networks (GPU-MPCNNs), now widely tested/used by research labs (e.g., Univ. Toronto/Google/Stanford) and companies (e.g., Apple) all over the world.
[6]
D. C. Ciresan, U. Meier, L. M. Gambardella, J. Schmidhuber.
Deep Big Simple Neural Nets For Handwritten Digit Recognition.
Neural Computation 22(12): 3207-3220, 2010.
ArXiv Preprint
arXiv:1003.0358v1 [cs.NE], 1 March 2010.
Best results on MNIST with plain backprop for standard NNs (no unsupervised pre-training, no convolution etc).
[5] A. Graves, A. Mohamed, G. E. Hinton. Speech Recognition with Deep Recurrent Neural Networks. ICASSP 2013, Vancouver, 2013.
PDF.
[4]
A. Graves, J. Schmidhuber.
Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks.
Advances in Neural Information Processing Systems 22, NIPS'22, p 545-552,
Vancouver, MIT Press, 2009.
PDF.
[3]
A. Graves, S. Fernandez, J. Schmidhuber. Multi-Dimensional Recurrent
Neural Networks.
Intl. Conf. on Artificial Neural Networks ICANN'07,
2007.
Preprint: arxiv:0705.2011.
PDF.
[3a] A. Graves, S. Fernandez, F. Gomez, J. Schmidhuber. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. ICML 06, Pittsburgh, 2006.
PDF.
Selected papers from the previous millennium
(more here):
[2j] F. A. Gers, J. Schmidhuber, F. Cummins. Learning to Forget: Continual Prediction with LSTM. Neural Computation, 12(10):2451-2471, 2000.
PDF.
[2i]
S. Hochreiter and J. Schmidhuber.
Feature extraction through LOCOCODE.
Neural Computation 11(3): 679-714, 1999.
PDF.
HTML (some pictures missing).
[2h]
N. N. Schraudolph, M. Eldracher, J. Schmidhuber.
Processing Images by Semi-Linear Predictability Minimization.
Network, 10(2): 133-169, 1999.
PDF.
[2g]
J. Schmidhuber and M. Eldracher and B. Foltin.
Semilinear predictability minimzation produces well-known
feature detectors.
Neural Computation, 8(4):773-786, 1996.
PDF .
HTML.
Facilitating supervised Bayes-optimal classification through unsupervised pre-training. Mentions a hierarchy of unsupervised PM stages.
[2f]
J. Schmidhuber and D. Prelinger.
Discovering
predictable classifications.
Neural Computation, 5(4):625-635, 1993.
PDF.
HTML. Compare "Siamese networks".
[2e]
J. Schmidhuber.
Learning factorial codes by predictability minimization.
Neural Computation, 4(6):863-879, 1992.
PDF.
HTML.
Partially motivated by speeding up supervised learning through unsupervised pre-processing.
[2d] S. Hochreiter, J. Schmidhuber. Long Short-Term Memory. Neural Computation, 9(8):1735-1780, 1997. Based on TR FKI-207-95, TUM (1995). PDF. Led to a lot of follow-up work, and is now used by leading IT companies all over the world.
[2c] J. Schmidhuber. Habilitation thesis, TUM, 1993. PDF. An ancient experiment with credit assignment across 1200 time steps or virtual layers and unsupervised pre-training for a stack of recurrent NNs
can be found here - try Google Translate in your mother tongue.
[2b] S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, TUM, 1991 (advisor J.S.) PDF.
[2a] J. Schmidhuber. Learning complex, extended sequences using the principle of history compression, Neural Computation, 4(2):234-242, 1992 (based on TR FKI-148-91, 1991). PDF.
[1b]
J. Schmidhuber.
A local learning algorithm for dynamic feedforward and
recurrent networks.
Connection Science, 1(4):403-412, 1989.
PDF.
HTML.
Local competition in the Neural Bucket Brigade (figures omitted).
[1a] J. Schmidhuber, R. Huber. Learning to generate artificial fovea trajectories for target detection. International Journal of Neural Systems, 2(1 & 2):135-141, 1991 (figures omitted). Based on TR FKI-128-90, 1990. PDF. HTML. HTML overview with figures. More on active learning without a teacher in the overview pages on the Formal Theory of Creativity and Curiosity. Our algorithms not only were the first Very Deep Learners to win official international competitions with secret test sets (since 2009) and to become human-competitive, they also have numerous immediate industrial and medical applications. Apple & Google and many others adopted our techniques. Are you an industrial company that wants to solve interesting pattern recognition problems? Don't hesitate to contact JS. By 2011-12, we already had developed: 1. State-of-the-art handwriting recognition for a software services company.
Much more on this has been done by our company NNAISENSE. Commercial News of 26 Jan 2014: Google acquired for about $600 million the startup Deepmind which is heavily influenced by our former students. Deepmind focuses on Machine Learning (ML) and AI, explicitly mentioning general purpose learning algorithms (more on our work on this here). Deepmind's first members with PhDs in computer science and publications in ML/AI came from my lab: Shane Legg (co-founder) and Daan Wierstra (#4 of Deepmind). Background of the other co-founders: neurobiology & video games (Demis Hassabis) and business (Mustafa Suleyman). Deepmind later also hired my former PhD students Tom Schaul & Alex Graves. They have been working on our deep RNNs: Alex on supervised RNNs, Daan & Tom on RL RNNs and Evolving RNNs (see their papers under the links above). Alex & Daan are also co-authors of one of the earliest deepmind publications (Dec 2013); compare our Compressed Network Search for RNN video game controllers learning from high-dim visual input streams (July 2013). Alex is also lead author of DeepMind's recent Nature paper (2016). See this news link and comments on deepmind's Nature paper (2015) and earlier related work. Selected invited talks 2010-16: Numerous invited keynotes / plenary talks etc. at international conferences, e. g., keynote for SAP for 6000 people (Barcelona, 10 Jan 2017), ZEIT Reception (WEF Davos, 18 Jan 2017), DLD (Munich, 15-16 Jan 2017), Boston Consulting (Chicago, 17-18 Nov 2016), TED-style talk for WIRED 2016 (London, 4 Nov 2016), General Electric (New York, 12-14 Oct 2016), NVIDIA GTC conference (Amsterdam, 28 Sept 2016), Public Interview for ZEIT (Berlin, Sept 2016), CONLL keynote (Berlin, Aug 2016), IJCNN 2016 plenary talk (Vancouver, July 2016), EU Communication Summit keynote (Bruxelles, July 2016), BMW & Modern Media Group (Beijing, May 2016), Pictet (London, May 2016), Microsoft (NYC, May 2016), TED-style talk for Pathfinder Berlin (Handelsblatt 70th anniversary, May 2016), TED-style talk for DLD (Munich, Jan 2016), GRI Chairman Retreat (St. Moritz, Jan 2016), Renaissance Technologies (NYC, Dec 2015), Big Data Conference (Stuttgart, Oct 2015), Financial Times (London, Nov 2015), Delft Robotics (NL, Oct 2015), 2015 Keynote for Swiss eHealth summit, 2015 IEEE distinguished lecture / Microsoft, Amazon (Seattle), 2015 INNS BigData (San Francisco), AGI 2015 keynote (Berlin), BigTechDay keynote (Munich, 2015), Uhlenbruch Portfolio Management (Frankfurt, 2015), Huawei STW 2015 keynote (Shenzhen / Hongkong), TED-style talk for XPRIZE 2015 (Los Angeles), INNS-CIIS 2014 keynote (Brunei), ICONIP 2014 (Malaysia), KAIST 2014 (Korea), CIG 2013 keynote (Niagara Falls), TEDx UHasselt 2012, TEDx Lausanne 2012, Bionetics 2012 keynote, IScIDE 2012 keynote (Nanjing, China), IJCNN 2011 (San Jose, California), World Science Festival 2011 (New York City), Oxford Winter Conference on Intelligence 2011, Joint Conferences ECML 2010 / PKDD 2010 (Barcelona; banquet talk). Check out talk slides of 2015! Copyright notice (2013):
This page was derived from the computer vision page.
Fibonacci web design by
J.S.,
who
will be delighted if you use this web page
for educational and non-commercial purposes, including
articles for
Wikipedia and similar sites.
Last update 2017.
|
![GPUs used for the work described in: High-Performance Neural Networks for Visual Object Classification, arXiv:1102.0183v1 [cs.AI]. (Juergen Schmidhuber)](gpu178+6.gif)


COMPETITION DETAILS
Links to the original datasets of competitions 1-9 and benchmarks A-D mentioned in the leftmost column, plus more information on the world records set by our team:
9. 22 Sept 2013: our deep and wide MC GPU-MPCNNs [8,17,18] won the MICCAI 2013 Grand Challenge on Mitosis Detection (important for cancer prognosis etc). This was made possible through the efforts of Dan and Alessandro [20]. Do not confuse this with the earlier ICPR 2012 contest below! Comment: When we started our work on Very Deep Learning over two decades ago, limited computing power forced us to focus on tiny toy applications to illustrate the benefits of our methods. How things have changed! It is gratifying to observe that today our techniques may actually help to improve healthcare and save lives.

D. As of 1 Sep 2013, our Deep Learning Neural Networks are the best artificial offline recognisers of Chinese characters from the ICDAR 2013 competition (3755 classes), approaching human performance [23]. This is relevant for smartphone producers who want to build phones that can translate photos of foreign texts and signs. As always in such competitions, GPU-based pure supervised gradient descent (40-year-old backprop) was applied to deep and wide multi-column networks with interleaving max-pooling layers and convolutional layers (multi-column GPU-MPCNNs) [8,17]. Many leading IT companies and research labs are now using this technique, too.
8. ICPR 2012 Contest on Mitosis Detection in Breast Cancer Histological Images (MITOS Aperio images). There were 129 registered companies / institutes / universities from 40 countries, and 14 results. Our team (with Alessandro & Dan) clearly won the contest (over 20% fewer errors than the second best team). This was the first Deep Learner to win a contest on object detection in large images, the first to win a medical imaging contest, and the first to win cancer detection contests. See ref [20], as well as the later MICCAI 2013 Grand Challenge above.
7. ISBI 2012 Segmentation of neuronal structures in EM stacks challenge. See the TrakEM2 data sets of INI. Our team won the contest on all three evaluation metrics by a large margin, with superhuman performance in terms of pixel error (March 2012) [15]. (First pure image segmentation competition won by a Deep Learner; ranks 2-6 for researchers at ETHZ, MIT, CMU, Harvard.) This is relevant for the recent huge brain projects in Europe and the US, which try to build 3D models of real brains.


6. IJCNN 2011 on-site Traffic Sign Recognition Competition (1st rank, 2 August 2011, 0.56% error rate, the only method better than humans, who achieved 1.16% on average; 3rd place for 1.69%) [10,18]. The first method ever to achieve superhuman visual pattern recognition on an important benchmark (with secret test set known only to the organisers). This is obviously relevant for self-driving cars.

5. The Chinese Handwriting Recognition Competition at ICDAR 2011 (offline). Our team won 1st and 2nd rank (CR(1): 92.18% correct; CR(10): 99.29% correct) in June 2011. This was the first pure, deep GPU-CNN to win an international pattern recognition contest - very important for all those cell phone makers who want to build smartphones that can read signs and restaurant menus in foreign languages. This attracted a lot of industry attention - it became clear that this was the way forward in computer vision.
4. INI @ Univ. Bochum's online German Traffic Sign Recognition Benchmark (the qualifying), won through late night efforts of Dan & Ueli & Jonathan (1st & 2nd rank; 1.02% error rate, January 2011) [10]. More.

C. The MNIST dataset of NY University, 1998. Our team set the new record (0.35% error rate) in 2010 [6] (through plain backprop without convolution or unsupervised pre-training), tied it again in January 2011 [8], broke it again in March 2011 (0.31%) [9], and again (0.27%, ICDAR 2011) [12], and finally achieved the first human-competitive result: 0.23% [17] (mean of many runs; many individual runs yield better results, of course, down to 0.17% [12]). This represented a dramatic improvement, since by then the MNIST record had hovered around 0.4% for almost a decade.
B. NORB object recognition dataset for stereo images, NY University, 2004. Our team set the new record on the standard set (2.53% error rate) in January 2011 [8], and achieved 2.7% on the full set [17] (best previous result by others: 5%).
A. The CIFAR-10 dataset of Univ. Toronto, 2009. Our team set the new record (19.51% error rate) on these rather challenging data in January 2011 [8], and improved this to 11.2% [17].
Three Connected Handwriting Recognition Competitions at ICDAR 2009 were won by our multi-dimensional LSTM recurrent neural networks [3,3a,4] through the efforts of Alex. This was the first RNN system ever to win an official international pattern recognition competition. To our knowledge, this also was the first Very Deep Learning system ever (recurrent or not) to win such contests:
3. ICDAR 2009 Arabic Connected Handwriting Competition of Univ. Braunschweig
2. ICDAR 2009 Handwritten Farsi/Arabic Character Recognition Competition
1. ICDAR 2009 French Connected Handwriting Competition (PDF) based on data from the RIMES campaign
Note that 1-3,C,D are treated in more detail in the page on handwriting recognition.
Here a 12 min Google Tech Talk video on fast deep / recurrent nets (only slides and voice) at AGI 2011, summarizing results as of August 2011:

People keep asking: What is the secret of your successes? There are actually two secrets:
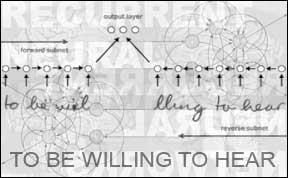
(i) For competitions involving sequential data such as video and speech we use our deep (stacks [2a] of) multi-dimensional [3] Long Short-Term Memory (LSTM) recurrent networks (1997) [2d,2j] trained by Connectionist Temporal Classification (CTC, 2006) [3a]. This is what since 2009 has set records in recognising connected handwriting [4] and speech, e.g., [5].

(ii) For other competitions we use multi-column (MC) committees [10] of GPU-MPCNNs (2011) [8], where we apply (in the style of LeCun et al 1989 & Ranzato et al 2007) efficient backpropagation (Linnainmaa 1970, Werbos 1981) to deep Neocognitron-like weight-replicating convolutional architectures (Fukushima 1979) with max-pooling (MP) layers (Weng 1992, Riesenhuber & Poggio 1999). Over two decades, LeCun's lab has invented many improvements of such CNNs. Our GPU-MPCNNs achieved the first superhuman image recognition results (2011) [18], and were the first Deep Learners to win contests in object detection (2012) and image segmentation (2012), which require fast, non-redundant MPCNN image scans [21,22].
Inaugural tweet: In 2020, we will celebrate that many of the basic ideas behind the Deep Learning Revolution were published three decades ago within fewer than 12 months in our "Annus Mirabilis" 1990-1991:

For more information on how we have built on the work of earlier pioneers since the 1960s, see www.deeplearning.me and especially this historical survey).

Deep recurrent networks can also reinforcement-learn through Compressed Network Search:

See this youtube video of a talk at CogX, London, 2018 (compare old slides from 2014 and a still more popular TEDx talk of 2017):

Check out our Brainstorm Open Source Software for Neural Networks:

Microsoft dominated the ImageNet 2015 contest through a deep feedforward LSTM without gates, a special case of our Highway Networks ([28], May 2015), the first very deep feedforward networks with hundreds of layers:

2016 IEEE CIS Neural Networks Pioneer Award awarded to JS for "pioneering contributions to deep learning and neural networks:"

Our deep learning methods have transformed machine learning and Artificial Intelligence (AI), and are now available to billions of users through the world's five most valuable public companies: Apple (#1 as of March 31, 2017), Google (Alphabet, #2), Microsoft (#3), Facebook (#4), and Amazon (#5).
.