


Next: 2. MODEL BUILDING WITH
Up: REINFORCEMENT DRIVEN INFORMATION ACQUISITION
Previous: REINFORCEMENT DRIVEN INFORMATION ACQUISITION
Efficient reinforcement learning requires to model the environment.
What is an efficient strategy for
acquiring a model of a non-deterministic Markov environment (NME)?
Reinforcement driven information acquisistion (RDIA), the method
described in this paper, extends
previous work on
``query learning'' and ``experimental design''
(see e.g. [3] for an overview,
see [1,6,4,7,2]
for more recent contributions)
and ``active exploration'',
e.g. [9,8,11].
The method
combines the notion of information gain
with the notion of reinforcement learning.
The latter is used to devise exploration strategies that
maximize the former.
Experiments demonstrate significant advantages of RDIA.
Basic set-up / Q-Learning.
An agent lives in a NME.
At a given discrete time step 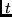 , the environment is in state
, the environment is in state  (one of
(one of 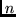 possible states
possible states
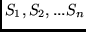 ), and
the agent executes action
), and
the agent executes action 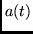 (one of
(one of 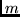 possible
actions
possible
actions
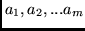 ).
This affects the environmental state:
If
).
This affects the environmental state:
If 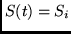 and
and 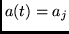 , then
with probability
, then
with probability 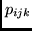 ,
, 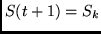 .
At certain times , there is reinforcement
.
At certain times , there is reinforcement 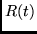 .
At time , the goal is to maximize the discounted sum of future
reinforcement
.
At time , the goal is to maximize the discounted sum of future
reinforcement
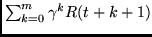 (where
(where
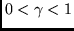 ).
We use Watkins' Q-learning [12] for this purpose:
).
We use Watkins' Q-learning [12] for this purpose:
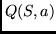 is the agent's evaluation (initially zero)
corresponding to the state/action pair
is the agent's evaluation (initially zero)
corresponding to the state/action pair 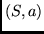 .
The central loop of the algorithm is as follows:
.
The central loop of the algorithm is as follows:
1. Observe current state .
Randomly choose
![$p \in [0, \ldots, 1]$](img17.png) .
If
.
If
![$p \leq \mu \in \left[0, \ldots, 1 \right]$](img18.png) ,
randomly pick .
Otherwise pick
such that
,
randomly pick .
Otherwise pick
such that 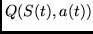 is maximal.
is maximal.
2. Execute , observe 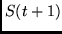 and
and 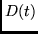 .
.
3.
where
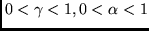 .
Goto 1.
.
Goto 1.
Next: 2. MODEL BUILDING WITH
Up: REINFORCEMENT DRIVEN INFORMATION ACQUISITION
Previous: REINFORCEMENT DRIVEN INFORMATION ACQUISITION
Juergen Schmidhuber
2003-02-28
Back to Active Learning - Exploration - Curiosity page
Back to Reinforcement Learning page